퀵정렬은 이름만 듣기에는 정렬 알고리즘중에서 가장 빠를것 같다는 오해를 불러 일으킬 수 있다. 하지만 퀵정렬은 정렬알고리즘 가운데 가장 빠른 알고리즘은 아니다. 하지만 실용적인 속도는 보장한다. 그리고 전형적인 재귀 알고리즘이지만 비재귀로도 가능하기에 꽤나 괜찮은 알고리즘 중에 하나다.
특징적인 것은 Pivot을 두고 왼쪽은 Pivot보다 작은 데이타 오른쪽은 Pivot보다 큰 데이타 이런식으로 정렬 해나가는 알고리즘이다. 이것을 재귀적으로 수행해 나가며 최후에 분할된 데이터의 사이즈가 1이 될경우 종료된다.
퀵정렬의 구현은 아래와 같다. 참고 도서에는 피벗을 우측에 데이터로 해서 구현해 뒀는데 난 반대로 좌측에 두고 구현해 보았다.
<성능 테스트>
| 데이터 갯수 | 수행시간 |
| 10000 | 2 |
| 20000 | 4 |
난수라서 다행히 스택 오버 플로우는 발생하지 않았다. 하지만 역순이라면 스택오버 플로우가 발생하게 된다. 이를 방지하기위해 비재귀로 바꿔줄 필요가 있다.
이는 추후에 추가를
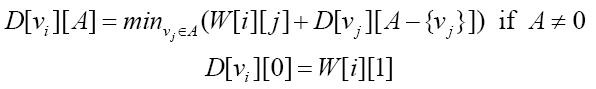

 invalid-file
invalid-file



